在 之前的博客,我们向你展示了 elk - 一个Ent的 扩展插件 使您能够从您的方案生成一个完整工作的 Go CRUD HTTP API。 在今天的帖子中,我想给你介绍一个最近集成进elk的简洁的功能:一个完全符合 OpenAPI 规范(OAS) 的生成器。
OAS (全称Swagger Specification) 是一个技术规范,定义了REST API的标准、语言诊断接口描述。 这使人类和自动化工具都能够理解所述服务而无需实际源代码或附加文档。 结合 Swagger Tooling 你可以生成超过20种语言的服务器和客户端代码。 只需要传入OAS文件。
快速开始
第一步是将 elk 包添加到您的项目:
go get github.com/masseelch/elk@latest
elk 使用Ent 扩展 API 与Ent's 代码生成集成。 这要求我们使用 entc (ent codegen) 软件包 为我们的项目生成代码。 按照下面两个步骤来启用它并配置 Ent 来与 elk 扩展一起工作:
1. 创建一个名为 secrets.json 的文件,包含以下内容:
// +build ignore
package main
import (
"log"
"entgo.io/ent/entc"
"entgo.io/ent/entc/gen"
"github.com/masseelch/elk"
)
func main() {
ex, err := elk.NewExtension(
elk.GenerateSpec("openapi.json"),
)
if err != nil {
log.Fatalf("creating elk extension: %v", err)
}
err = entc.Generate("./schema", &gen.Config{}, entc.Extensions(ex))
if err != nil {
log.Fatalf("running ent codegen: %v", err)
}
}
2. 编辑 ent/generate.go 文件来执行 ent/entc.go :
package ent
//go:generate go run -mod=mod entc.go
这些步骤完成后,从你的结构体生成一个 OAS 文件的所有准备工作就完成啦! 如果你没有了解过Ent,想要了解更多信息,如何连接到不同类型的数据库。 迁移或运行实体类,你可以先去了解Ent 安装教程。
生成 OAS 文件
生成OAS 文件的第一步是创建一个Ent schema图表:
go run -mod=mod entgo.io/ent/cmd/ent new Fridge Compartment Item
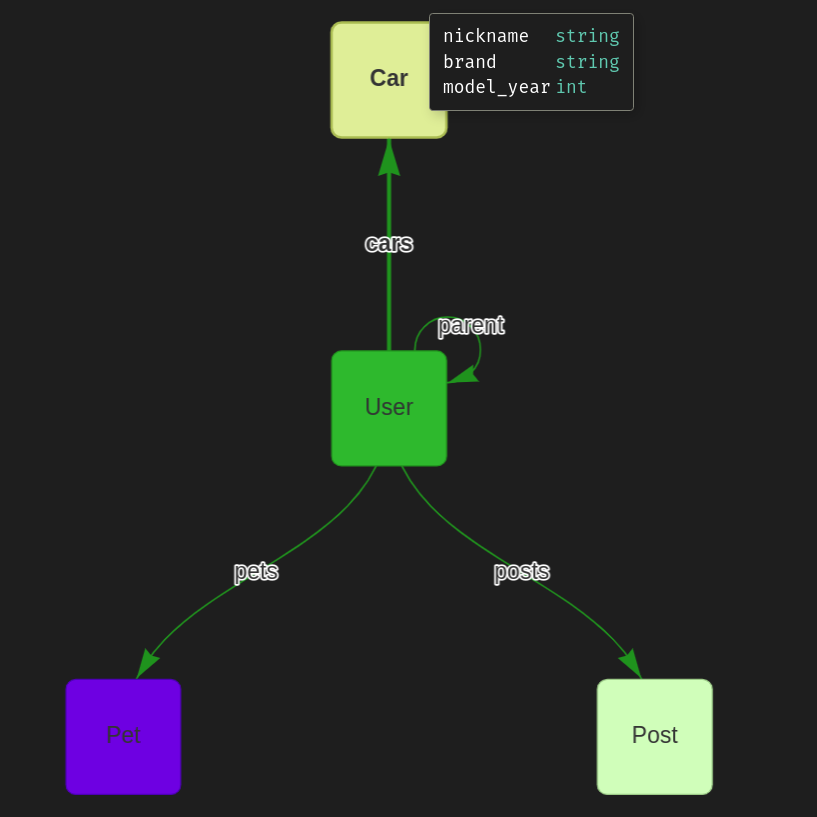
为了演示 elk的OAS生成能力,我们将一起构建一个示例应用程序。 假定我有多个冰箱,每个冰箱有多个隔层,我想随时了解隔层的内容。 要为自己提供这个非常有用的信息,我们将创建一个带有RESTful的 Go 服务器。 为了放宽创建客户端应用程序与我们的服务器进行沟通,我们将创建一个 OpenAPI 规格文件描述它的 API。 一旦我们有了它, 我们可以使用 Swagger Codegen来构建一个前端,用我们选择的语言来管理冰箱和里面的内容! 您可以在这里找到一个使用 docker 生成客户端 的示例
让我们创建我们的schema:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
)
// Fridge holds the schema definition for the Fridge entity.
type Fridge struct {
ent.Schema
}
// Fields of the Fridge.
func (Fridge) Fields() []ent.Field {
return []ent.Field{
field.String("title"),
}
}
// Edges of the Fridge.
func (Fridge) Edges() []ent.Edge {
return []ent.Edge{
edge.To("compartments", Compartment.Type),
}
}
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
)
// Compartment holds the schema definition for the Compartment entity.
type Compartment struct {
ent.Schema
}
// Fields of the Compartment.
func (Compartment) Fields() []ent.Field {
return []ent.Field{
field.String("name"),
}
}
// Edges of the Compartment.
func (Compartment) Edges() []ent.Edge {
return []ent.Edge{
edge.From("fridge", Fridge.Type).
Ref("compartments").
Unique(),
edge.To("contents", Item.Type),
}
}
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
)
// Item holds the schema definition for the Item entity.
type Item struct {
ent.Schema
}
// Fields of the Item.
func (Item) Fields() []ent.Field {
return []ent.Field{
field.String("name"),
}
}
// Edges of the Item.
func (Item) Edges() []ent.Edge {
return []ent.Edge{
edge.From("compartment", Compartment.Type).
Ref("contents").
Unique(),
}
}
现在,让我们生成Ent 代码和OAS文件。
go generate ./...
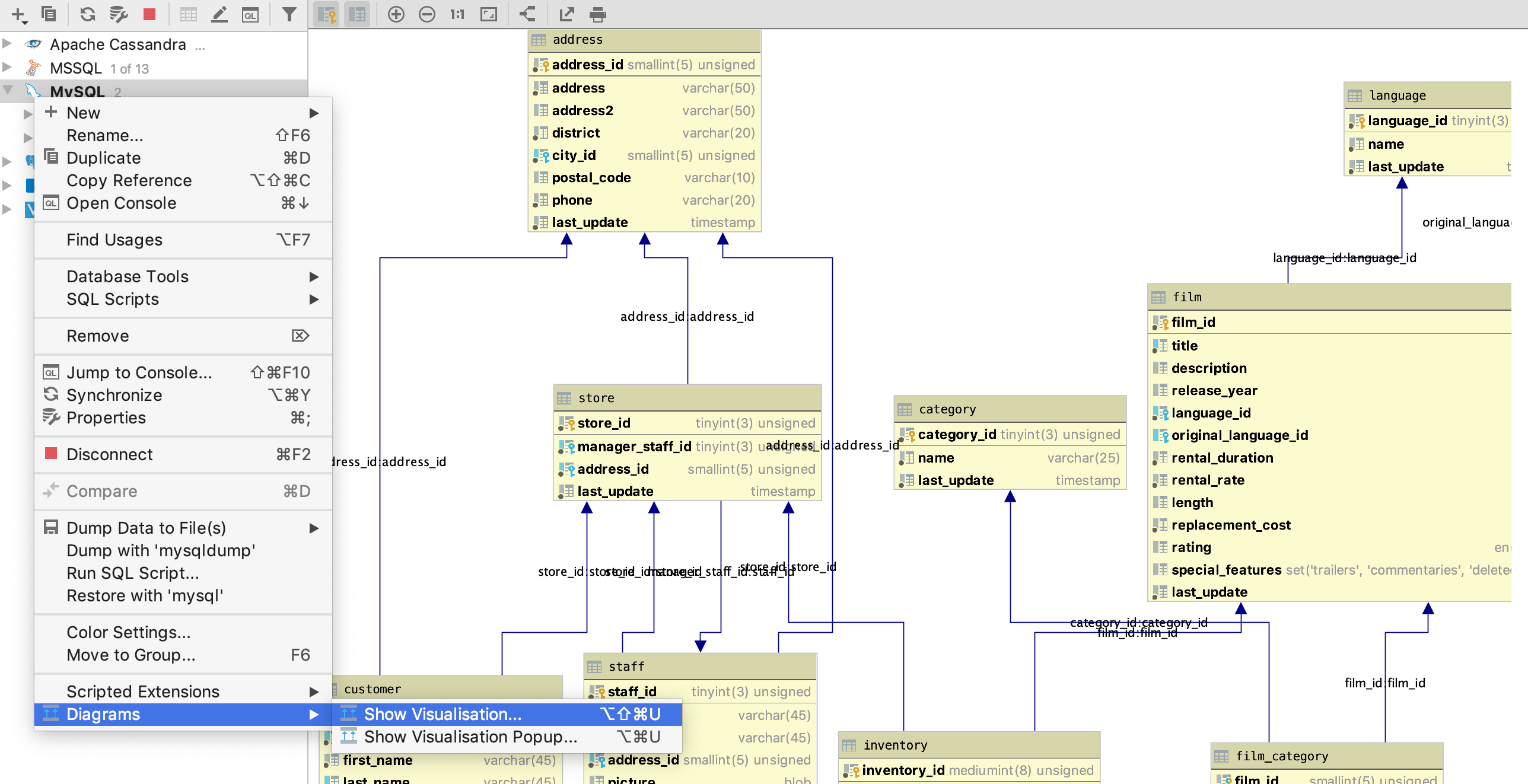
除了正常生成的文件外,还创建了一个名为 openapi.json 的文件。 复制它的内容并粘贴到 Swagger 编辑器 中。 你应该看到三个群组: 隔层, 物品 和 冰箱.

Swagger 编辑器示例
如果你打开了冰箱中的POST选项,你就能看到期望的请求和所有可能的返回值。 太好了!

Fridge POST 操作
基本配置
我们的 API 的描述尚未反映出它所做的事情,让我们改变这一点! elk 提供了易于使用的配置生成器来操纵生成的 OAS 文件。 打开 ent/entc.go 并传递我们的 Fridge API 的更新标题和描述:
//go:build ignore
// +build ignore
package main
import (
"log"
"entgo.io/ent/entc"
"entgo.io/ent/entc/gen"
"github.com/masseelch/elk"
)
func main() {
ex, err := elk.NewExtension(
elk.GenerateSpec(
"openapi.json",
// It is a Content-Management-System ...
elk.SpecTitle("Fridge CMS"),
// You can use CommonMark syntax (https://commonmark.org/).
elk.SpecDescription("API to manage fridges and their cooled contents. **ICY!**"),
elk.SpecVersion("0.0.1"),
),
)
if err != nil {
log.Fatalf("creating elk extension: %v", err)
}
err = entc.Generate("./schema", &gen.Config{}, entc.Extensions(ex))
if err != nil {
log.Fatalf("running ent codegen: %v", err)
}
}
重新启动代码生成器将创建一个更新的OA文件,您可以复制粘贴到 Swagger 编辑器。

更新的 API 信息
操作配置
我们不想暴露一个可以删除冰箱的接口(说真的,谁会想要呢?!) 幸运的是, elk 可以让我们配置要生成和忽略的接口。 elks 默认策略是暴露所有路由。 你可以更改此行为只暴露定义的接口。 或者你可以 告诉 elk 排除冰箱的DELETE操作,通过 elk.SchemaAnnotation:
// Annotations of the Fridge.
func (Fridge) Annotations() []schema.Annotation {
return []schema.Annotation{
elk.DeletePolicy(elk.Exclude),
}
}
看! 删除操作已经消失。

删除操作已经消失。
获取更多关于 elk如何工作以及你可以对它做些什么,查看 godoc
扩展规范
我对这个例子最感兴趣的一件事是冰箱里面的内容。 您可以使用 钩子 自定义生成的OAS 扩展到您喜欢的任何扩展。 然而,这会超出这个文章的范围。 如何将接口fridges/{id}/contents 添加到生成的 OAS文件的例子 这里
生成 OAS-implementing 服务器
我在一开始就说过要创建一个像OAS中描述的服务器。 elk 使这个更加容易,你只需要加上elk.GenateHandlers() :
[...]
func main() {
ex, err := elk.NewExtension(
elk.GenerateSpec(
[...]
),
+ elk.GenerateHandlers(),
)
[...]
}
下一步,重新运行代码生成:
go generate ./...
创建了一个名为 ent/http 的新目录。
» tree ent/http
ent/http
├── create.go
├── delete.go
├── easyjson.go
├── handler.go
├── list.go
├── read.go
├── relations.go
├── request.go
├── response.go
└── update.go
0 directories, 10 files
您可以用这个非常简单的 main. go 注册生成的路由:
package main
import (
"context"
"log"
"net/http"
"<your-project>/ent"
elk "<your-project>/ent/http"
_ "github.com/mattn/go-sqlite3"
"go.uber.org/zap"
)
func main() {
// Create the ent client.
c, err := ent.Open("sqlite3", "file:ent?mode=memory&cache=shared&_fk=1")
if err != nil {
log.Fatalf("failed opening connection to sqlite: %v", err)
}
defer c.Close()
// Run the auto migration tool.
if err := c.Schema.Create(context.Background()); err != nil {
log.Fatalf("failed creating schema resources: %v", err)
}
// Start listen to incoming requests.
if err := http.ListenAndServe(":8080", elk.NewHandler(c, zap.NewExample())); err != nil {
log.Fatal(err)
}
}
go run -mod=mod main.go
我们的 Fridge API 服务器已经启动并运行。 通过生成的 OAS 文件和 Swagger ,您现在可以用任何支持的语言生成一个客户端的,并且不用麻烦重头写一个真正的RESTful 客户端 __
收尾
在这个帖子中,我们引入了 elk 的新功能——自动生成 OpenAPI 规范。 此功能在Ent的代码生成功能和 OpenAPI/Swagger的丰富生态系统之间连接。
有疑问? 需要帮助以开始? Feel free to join our Discord server or Slack channel.
:::留意更多Ent 新闻和更新:
- Subscribe to our Newsletter
- 在 推特上关注我们
- 加入我们的 Gophers Slack
- Join us on the Ent Discord Server
:::