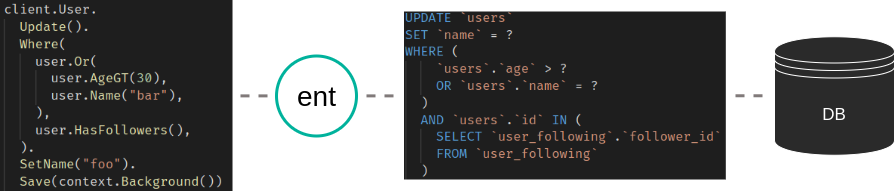
When Ariel released Ent v0.10.0 at the end of January, he introduced a new migration engine for Ent based on another open-source project called Atlas.
Initially, Atlas supported a style of managing database schemas that we call "declarative migrations". With declarative migrations, the desired state of the database schema is given as input to the migration engine, which plans and executes a set of actions to change the database to its desired state. This approach has been popularized in the field of cloud native infrastructure by projects such as Kubernetes and Terraform. It works great in many cases, in fact it has served the Ent framework very well in the past few years. However, database migrations are a very sensitive topic, and many projects require a more controlled approach.
For this reason, most industry standard solutions, like Flyway , Liquibase, or golang-migrate/migrate (which is common in the Go ecosystem), support a workflow that they call "versioned migrations".
With versioned migrations (sometimes called "change base migrations") instead of describing the desired state ("what the database should look like"), you describe the changes itself ("how to reach the state"). Most of the time this is done by creating a set of SQL files containing the statements needed. Each of the files is assigned a unique version and a description of the changes. Tools like the ones mentioned earlier are then able to interpret the migration files and to apply (some of) them in the correct order to transition to the desired database structure.
In this post, I want to showcase a new kind of migration workflow that has recently been added to Atlas and Ent. We call it "versioned migration authoring" and it's an attempt to combine the simplicity and expressiveness of the declarative approach with the safety and explicitness of versioned migrations. With versioned migration authoring, users still declare their desired state and use the Atlas engine to plan a safe migration from the existing to the new state. However, instead of coupling the planning and execution, it is instead written into a file which can be checked into source control, fine-tuned manually and reviewed in normal code review processes.
As an example, I will demonstrate the workflow with golang-migrate/migrate.
Getting Started
The very first thing to do, is to make sure you have an up-to-date Ent version:
go get -u entgo.io/ent@master
There are two ways to have Ent generate migration files for schema changes. The first one is to use an instantiated Ent client and the second one to generate the changes from a parsed schema graph. This post will take the second approach, if you want to learn how to use the first one you can have a look at the documentation.
Generating Versioned Migration Files
Since we have enabled the versioned migrations feature now, let's create a small schema and generate the initial set of migration files. Consider the following schema for a fresh Ent project:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/field"
"entgo.io/ent/schema/index"
)
// User holds the schema definition for the User entity.
type User struct {
ent.Schema
}
// Fields of the User.
func (User) Fields() []ent.Field {
return []ent.Field{
field.String("username"),
}
}
// Indexes of the User.
func (User) Indexes() []ent.Index {
return []ent.Index{
index.Fields("username").Unique(),
}
}
As I stated before, we want to use the parsed schema graph to compute the difference between our schema and the connected database. Here is an example of a (semi-)persistent MySQL docker container to use if you want to follow along:
docker run --rm --name ent-versioned-migrations --detach --env MYSQL_ROOT_PASSWORD=pass --env MYSQL_DATABASE=ent -p 3306:3306 mysql
Once you are done, you can shut down the container and remove all resources with docker stop ent-versioned-migrations.
Now, let's create a small function that loads the schema graph and generates the migration files. Create a new Go file named main.go and copy the following contents:
package main
import (
"context"
"log"
"os"
"ariga.io/atlas/sql/migrate"
"entgo.io/ent/dialect/sql"
"entgo.io/ent/dialect/sql/schema"
"entgo.io/ent/entc"
"entgo.io/ent/entc/gen"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// We need a name for the new migration file.
if len(os.Args) < 2 {
log.Fatalln("no name given")
}
// Create a local migration directory.
dir, err := migrate.NewLocalDir("migrations")
if err != nil {
log.Fatalln(err)
}
// Load the graph.
graph, err := entc.LoadGraph("./ent/schema", &gen.Config{})
if err != nil {
log.Fatalln(err)
}
tbls, err := graph.Tables()
if err != nil {
log.Fatalln(err)
}
// Open connection to the database.
drv, err := sql.Open("mysql", "root:pass@tcp(localhost:3306)/ent")
if err != nil {
log.Fatalln(err)
}
// Inspect the current database state and compare it with the graph.
m, err := schema.NewMigrate(drv, schema.WithDir(dir))
if err != nil {
log.Fatalln(err)
}
if err := m.NamedDiff(context.Background(), os.Args[1], tbls...); err != nil {
log.Fatalln(err)
}
}
All we have to do now is create the migration directory and execute the above Go file:
mkdir migrations
go run -mod=mod main.go initial
You will now see two new files in the migrations directory: <timestamp>_initial.down.sql and <timestamp>_initial.up.sql. The x.up.sql files are used to create the database version x and x.down.sql to roll back to the previous version.
CREATE TABLE `users` (`id` bigint NOT NULL AUTO_INCREMENT, `username` varchar(191) NOT NULL, PRIMARY KEY (`id`), UNIQUE INDEX `user_username` (`username`)) CHARSET utf8mb4 COLLATE utf8mb4_bin;
DROP TABLE `users`;
Applying Migrations
To apply these migrations on your database, install the golang-migrate/migrate tool as described in their README. Then run the following command to check if everything went as it should.
migrate -help
Usage: migrate OPTIONS COMMAND [arg...]
migrate [ -version | -help ]
Options:
-source Location of the migrations (driver://url)
-path Shorthand for -source=file://path
-database Run migrations against this database (driver://url)
-prefetch N Number of migrations to load in advance before executing (default 10)
-lock-timeout N Allow N seconds to acquire database lock (default 15)
-verbose Print verbose logging
-version Print version
-help Print usage
Commands:
create [-ext E] [-dir D] [-seq] [-digits N] [-format] NAME
Create a set of timestamped up/down migrations titled NAME, in directory D with extension E.
Use -seq option to generate sequential up/down migrations with N digits.
Use -format option to specify a Go time format string.
goto V Migrate to version V
up [N] Apply all or N up migrations
down [N] Apply all or N down migrations
drop Drop everything inside database
force V Set version V but don't run migration (ignores dirty state)
version Print current migration version
Now we can execute our initial migration and sync the database with our schema:
migrate -source 'file://migrations' -database 'mysql://root:pass@tcp(localhost:3306)/ent' up
<timestamp>/u initial (349.256951ms)
Workflow
To demonstrate the usual workflow when using versioned migrations we will both edit our schema graph and generate the migration changes for it, and manually create a set of migration files to seed the database with some data. First, we will add a Group schema and a many-to-many relation to the existing User schema, next create an admin Group with an admin User in it. Go ahead and make the following changes:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
"entgo.io/ent/schema/index"
)
// User holds the schema definition for the User entity.
type User struct {
ent.Schema
}
// Fields of the User.
func (User) Fields() []ent.Field {
return []ent.Field{
field.String("username"),
}
}
// Edges of the User.
func (User) Edges() []ent.Edge {
return []ent.Edge{
edge.From("groups", Group.Type).
Ref("users"),
}
}
// Indexes of the User.
func (User) Indexes() []ent.Index {
return []ent.Index{
index.Fields("username").Unique(),
}
}
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
"entgo.io/ent/schema/index"
)
// Group holds the schema definition for the Group entity.
type Group struct {
ent.Schema
}
// Fields of the Group.
func (Group) Fields() []ent.Field {
return []ent.Field{
field.String("name"),
}
}
// Edges of the Group.
func (Group) Edges() []ent.Edge {
return []ent.Edge{
edge.To("users", User.Type),
}
}
// Indexes of the Group.
func (Group) Indexes() []ent.Index {
return []ent.Index{
index.Fields("name").Unique(),
}
}
Once the schema is updated, create a new set of migration files.
go run -mod=mod main.go add_group_schema
Once again there will be two new files in the migrations directory: <timestamp>_add_group_schema.down.sql and <timestamp>_add_group_schema.up.sql.
CREATE TABLE `groups` (`id` bigint NOT NULL AUTO_INCREMENT, `name` varchar(191) NOT NULL, PRIMARY KEY (`id`), UNIQUE INDEX `group_name` (`name`)) CHARSET utf8mb4 COLLATE utf8mb4_bin;
CREATE TABLE `group_users` (`group_id` bigint NOT NULL, `user_id` bigint NOT NULL, PRIMARY KEY (`group_id`, `user_id`), CONSTRAINT `group_users_group_id` FOREIGN KEY (`group_id`) REFERENCES `groups` (`id`) ON DELETE CASCADE, CONSTRAINT `group_users_user_id` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`) ON DELETE CASCADE) CHARSET utf8mb4 COLLATE utf8mb4_bin;
DROP TABLE `group_users`;
DROP TABLE `groups`;
Now you can either edit the generated files to add the seed data or create new files for it. I chose the latter:
migrate create -format unix -ext sql -dir migrations seed_admin
[...]/ent-versioned-migrations/migrations/<timestamp>_seed_admin.up.sql
[...]/ent-versioned-migrations/migrations/<timestamp>_seed_admin.down.sql
You can now edit those files and add statements to create an admin Group and User.
INSERT INTO `groups` (`id`, `name`) VALUES (1, 'Admins');
INSERT INTO `users` (`id`, `username`) VALUES (1, 'admin');
INSERT INTO `group_users` (`group_id`, `user_id`) VALUES (1, 1);
DELETE FROM `group_users` where `group_id` = 1 and `user_id` = 1;
DELETE FROM `groups` where id = 1;
DELETE FROM `users` where id = 1;
Apply the migrations once more, and you are done:
migrate -source file://migrations -database 'mysql://root:pass@tcp(localhost:3306)/ent' up
<timestamp>/u add_group_schema (417.434415ms)
<timestamp>/u seed_admin (674.189872ms)
Wrapping Up
In this post, we demonstrated the general workflow when using Ent Versioned Migrations with golang-migate/migrate. We created a small example schema, generated the migration files for it and learned how to apply them. We now know the workflow and how to add custom migration files.
Have questions? Need help with getting started? Feel free to join our Discord server or Slack channel.
- Subscribe to our Newsletter
- Follow us on Twitter
- Join us on #ent on the Gophers Slack
- Join us on the Ent Discord Server