
In this blog post, we will explore how to build a RAG (Retrieval Augmented Generation) system using Ent, Atlas, and pgvector.
RAG is a technique that augments the power of generative models by incorporating a retrieval step. Instead of relying solely on the model’s internal knowledge, we can retrieve relevant documents or data from an external source and use that information to produce more accurate, context-aware responses. This approach is particularly useful when building applications such as question-answering systems, chatbots, or any scenario where up-to-date or domain-specific knowledge is needed.
Setting Up our Ent schema
Let's begin our tutorial by initializing the Go module which we will be using for our project:
go mod init github.com/rotemtam/entrag # Feel free to replace the module path with your own
In this project we will use Ent, an entity framework for Go, to define our database schema. The database will store the documents we want to retrieve (chunked to a fixed size) and the vectors representing each chunk. Initialize the Ent project by running the following command:
go run -mod=mod entgo.io/ent/cmd/ent new Embedding Chunk
This command creates placeholders for our data models. Our project should look like this:
├── ent
│ ├── generate.go
│ └── schema
│ ├── chunk.go
│ └── embedding.go
├── go.mod
└── go.sum
Next, let's define the schema for the Chunk model. Open the ent/schema/chunk.go file and define the schema as follows:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
)
// Chunk holds the schema definition for the Chunk entity.
type Chunk struct {
ent.Schema
}
// Fields of the Chunk.
func (Chunk) Fields() []ent.Field {
return []ent.Field{
field.String("path"),
field.Int("nchunk"),
field.Text("data"),
}
}
// Edges of the Chunk.
func (Chunk) Edges() []ent.Edge {
return []ent.Edge{
edge.To("embedding", Embedding.Type).StorageKey(edge.Column("chunk_id")).Unique(),
}
}
This schema defines a Chunk entity with three fields: path, nchunk, and data. The path field stores the path
of the document, nchunk stores the chunk number, and data stores the chunked text data. We also define an edge to
the Embedding entity, which will store the vector representation of the chunk.
Before we proceed, let's install the pgvector package. pgvector is a PostgreSQL extension that provides support for
vector operations and similarity search. We will need it to store and retrieve the vector representations of our chunks.
go get github.com/pgvector/pgvector-go
Next, let's define the schema for the Embedding model. Open the ent/schema/embedding.go file and define the schema
as follows:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/dialect"
"entgo.io/ent/dialect/entsql"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
"entgo.io/ent/schema/index"
"github.com/pgvector/pgvector-go"
)
// Embedding holds the schema definition for the Embedding entity.
type Embedding struct {
ent.Schema
}
// Fields of the Embedding.
func (Embedding) Fields() []ent.Field {
return []ent.Field{
field.Other("embedding", pgvector.Vector{}).
SchemaType(map[string]string{
dialect.Postgres: "vector(1536)",
}),
}
}
// Edges of the Embedding.
func (Embedding) Edges() []ent.Edge {
return []ent.Edge{
edge.From("chunk", Chunk.Type).Ref("embedding").Unique().Required(),
}
}
func (Embedding) Indexes() []ent.Index {
return []ent.Index{
index.Fields("embedding").
Annotations(
entsql.IndexType("hnsw"),
entsql.OpClass("vector_l2_ops"),
),
}
}
This schema defines an Embedding entity with a single field embedding of type pgvector.Vector. The embedding
field stores the vector representation of the chunk. We also define an edge to the Chunk entity and an index on the
embedding field using the hnsw index type and vector_l2_ops operator class. This index will enable us to perform
efficient similarity searches on the embeddings.
Finally, let's generate the Ent code by running the following commands:
go mod tidy
go generate ./...
Ent will generate the necessary code for our models based on the schema definitions.
Setting Up the database
Next, let's set up the PostgreSQL database. We will use Docker to run a PostgreSQL instance locally. As we need the
pgvector extension, we will use the pgvector/pgvector:pg17 Docker image, which comes with the extension
pre-installed.
docker run --rm --name postgres -e POSTGRES_PASSWORD=pass -p 5432:5432 -d pgvector/pgvector:pg17
We will be using Atlas, a database schema-as-code tool that integrates with Ent, to manage our database schema. Install Atlas by running the following command:
curl -sSfL https://atlasgo.io/install.sh | sh
For other installation options, see the Atlas installation docs.
As we are going to managing extensions, we need an Atlas Pro account. You can sign up for a free trial by running:
atlas login
If you would like to skip using Atlas, you can apply the required schema directly to the database using the statements in this file
Now, let's create our base configuration base.pg.hcl which provides the vector extension for the public schema:
schema "public" {
}
extension "vector" {
schema = schema.public
}
Now, let's create our Atlas configuration which composes the base.pg.hcl file with the Ent schema:
data "composite_schema" "schema" {
schema {
url = "file://base.pg.hcl"
}
schema "public" {
url = "ent://ent/schema"
}
}
env "local" {
url = getenv("DB_URL")
schema {
src = data.composite_schema.schema.url
}
dev = "docker://pgvector/pg17/dev"
}
This configuration defines a composite schema that includes the base.pg.hcl file and the Ent schema. We also define an
environment named local that uses the composite schema which we will use for local development. The dev field specifies
the Dev Database URL, which is used by Atlas to normalize schemas and make
various calculations.
Next, let's apply the schema to the database by running the following command:
export DB_URL='postgresql://postgres:pass@localhost:5432/postgres?sslmode=disable'
atlas schema apply --env local
Atlas will load the desired state of the database from our configuration, compare it to the current state of the database, and create a migration plan to bring the database to the desired state:
Planning migration statements (5 in total):
-- create extension "vector":
-> CREATE EXTENSION "vector" WITH SCHEMA "public" VERSION "0.8.0";
-- create "chunks" table:
-> CREATE TABLE "public"."chunks" (
"id" bigint NOT NULL GENERATED BY DEFAULT AS IDENTITY,
"path" character varying NOT NULL,
"nchunk" bigint NOT NULL,
"data" text NOT NULL,
PRIMARY KEY ("id")
);
-- create "embeddings" table:
-> CREATE TABLE "public"."embeddings" (
"id" bigint NOT NULL GENERATED BY DEFAULT AS IDENTITY,
"embedding" public.vector(1536) NOT NULL,
"chunk_id" bigint NOT NULL,
PRIMARY KEY ("id"),
CONSTRAINT "embeddings_chunks_embedding" FOREIGN KEY ("chunk_id") REFERENCES "public"."chunks" ("id") ON UPDATE NO ACTION ON DELETE NO ACTION
);
-- create index "embedding_embedding" to table: "embeddings":
-> CREATE INDEX "embedding_embedding" ON "public"."embeddings" USING hnsw ("embedding" vector_l2_ops);
-- create index "embeddings_chunk_id_key" to table: "embeddings":
-> CREATE UNIQUE INDEX "embeddings_chunk_id_key" ON "public"."embeddings" ("chunk_id");
-------------------------------------------
Analyzing planned statements (5 in total):
-- non-optimal columns alignment:
-- L4: Table "chunks" has 8 redundant bytes of padding per row. To reduce disk space,
the optimal order of the columns is as follows: "id", "nchunk", "path",
"data" https://atlasgo.io/lint/analyzers#PG110
-- ok (370.25µs)
-------------------------
-- 114.306667ms
-- 5 schema changes
-- 1 diagnostic
-------------------------------------------
? Approve or abort the plan:
▸ Approve and apply
Abort
In addition to planning the change, Atlas will also provide diagnostics and suggestions for optimizing the schema. In this
case it suggests reordering the columns in the chunks table to reduce disk space. As we are not concerned with disk space
in this tutorial, we can proceed with the migration by selecting Approve and apply.
Finally, we can verify that our schema was applied successfully, we can re-run the atlas schema apply command. Atlas
will output:
Schema is synced, no changes to be made
Scaffolding the CLI
Now that our database schema is set up, let's scaffold our CLI application. For this tutorial, we will be using
the alecthomas/kong library to build a small app that can load, index
and query the documents in our database.
First, install the kong library:
go get github.com/alecthomas/kong
Next, create a new file named cmd/entrag/main.go and define the CLI application as follows:
package main
import (
"fmt"
"os"
"github.com/alecthomas/kong"
)
// CLI holds global options and subcommands.
type CLI struct {
// DBURL is read from the environment variable DB_URL.
DBURL string `kong:"env='DB_URL',help='Database URL for the application.'"`
OpenAIKey string `kong:"env='OPENAI_KEY',help='OpenAI API key for the application.'"`
// Subcommands
Load *LoadCmd `kong:"cmd,help='Load command that accepts a path.'"`
Index *IndexCmd `kong:"cmd,help='Create embeddings for any chunks that do not have one.'"`
Ask *AskCmd `kong:"cmd,help='Ask a question about the indexed documents'"`
}
func main() {
var cli CLI
app := kong.Parse(&cli,
kong.Name("entrag"),
kong.Description("Ask questions about markdown files."),
kong.UsageOnError(),
)
if err := app.Run(&cli); err != nil {
fmt.Fprintf(os.Stderr, "Error: %s\n", err)
os.Exit(1)
}
}
Create an additional file named cmd/entrag/rag.go with the following content:
package main
type (
// LoadCmd loads the markdown files into the database.
LoadCmd struct {
Path string `help:"path to dir with markdown files" type:"existingdir" required:""`
}
// IndexCmd creates the embedding index on the database.
IndexCmd struct {
}
// AskCmd is another leaf command.
AskCmd struct {
// Text is the positional argument for the ask command.
Text string `kong:"arg,required,help='Text for the ask command.'"`
}
)
Verify our scaffolded CLI application works by running:
go run ./cmd/entrag --help
If everything is set up correctly, you should see the help output for the CLI application:
Usage: entrag <command> [flags]
Ask questions about markdown files.
Flags:
-h, --help Show context-sensitive help.
--dburl=STRING Database URL for the application ($DB_URL).
--open-ai-key=STRING OpenAI API key for the application ($OPENAI_KEY).
Commands:
load --path=STRING [flags]
Load command that accepts a path.
index [flags]
Create embeddings for any chunks that do not have one.
ask <text> [flags]
Ask a question about the indexed documents
Run "entrag <command> --help" for more information on a command.
Load the documents into the database
Next, we need some markdown files to load into the database. Create a directory named data and add some markdown files
to it. For this example, I downloaded the ent/ent repository and used the docs directory
as the source of markdown files.
Now, let's implement the LoadCmd command to load the markdown files into the database. Open the cmd/entrag/rag.go file
and add the following code:
const (
tokenEncoding = "cl100k_base"
chunkSize = 1000
)
// Run is the method called when the "load" command is executed.
func (cmd *LoadCmd) Run(ctx *CLI) error {
client, err := ctx.entClient()
if err != nil {
return fmt.Errorf("failed opening connection to postgres: %w", err)
}
tokTotal := 0
return filepath.WalkDir(ctx.Load.Path, func(path string, d fs.DirEntry, err error) error {
if filepath.Ext(path) == ".mdx" || filepath.Ext(path) == ".md" {
chunks := breakToChunks(path)
for i, chunk := range chunks {
tokTotal += len(chunk)
client.Chunk.Create().
SetData(chunk).
SetPath(path).
SetNchunk(i).
SaveX(context.Background())
}
}
return nil
})
}
func (c *CLI) entClient() (*ent.Client, error) {
return ent.Open("postgres", c.DBURL)
}
This code defines the Run method for the LoadCmd command. The method reads the markdown files from the specified
path, breaks them into chunks of 1000 tokens each, and saves them to the database. We use the entClient method to
create a new Ent client using the database URL specified in the CLI options.
For the implementation of breakToChunks, see the full code
in the entrag repository, which is based almost entirely on
Eli Bendersky's intro to RAG in Go.
Finally, let's run the load command to load the markdown files into the database:
go run ./cmd/entrag load --path=data
After the command completes, you should see the chunks loaded into the database. To verify run:
docker exec -it postgres psql -U postgres -d postgres -c "SELECT COUNT(*) FROM chunks;"
You should see something similar to:
count
-------
276
(1 row)
Indexing the embeddings
Now that we have loaded the documents into the database, we need to create embeddings for each chunk. We will use the
OpenAI API to generate embeddings for the chunks. To do this, we need to install the openai package:
go get github.com/sashabaranov/go-openai
If you do not have an OpenAI API key, you can sign up for an account on the OpenAI Platform and generate an API key.
We will be reading this key from the environment variable OPENAI_KEY, so let's set it:
export OPENAI_KEY=<your OpenAI API key>
Next, let's implement the IndexCmd command to create embeddings for the chunks. Open the cmd/entrag/rag.go file and
add the following code:
// Run is the method called when the "index" command is executed.
func (cmd *IndexCmd) Run(cli *CLI) error {
client, err := cli.entClient()
if err != nil {
return fmt.Errorf("failed opening connection to postgres: %w", err)
}
ctx := context.Background()
chunks := client.Chunk.Query().
Where(
chunk.Not(
chunk.HasEmbedding(),
),
).
Order(ent.Asc(chunk.FieldID)).
AllX(ctx)
for _, ch := range chunks {
log.Println("Created embedding for chunk", ch.Path, ch.Nchunk)
embedding := getEmbedding(ch.Data)
_, err := client.Embedding.Create().
SetEmbedding(pgvector.NewVector(embedding)).
SetChunk(ch).
Save(ctx)
if err != nil {
return fmt.Errorf("error creating embedding: %v", err)
}
}
return nil
}
// getEmbedding invokes the OpenAI embedding API to calculate the embedding
// for the given string. It returns the embedding.
func getEmbedding(data string) []float32 {
client := openai.NewClient(os.Getenv("OPENAI_KEY"))
queryReq := openai.EmbeddingRequest{
Input: []string{data},
Model: openai.AdaEmbeddingV2,
}
queryResponse, err := client.CreateEmbeddings(context.Background(), queryReq)
if err != nil {
log.Fatalf("Error getting embedding: %v", err)
}
return queryResponse.Data[0].Embedding
}
We have defined the Run method for the IndexCmd command. The method queries the database for chunks that do not have
embeddings, generates embeddings for each chunk using the OpenAI API, and saves the embeddings to the database.
Finally, let's run the index command to create embeddings for the chunks:
go run ./cmd/entrag index
You should see logs similar to:
2025/02/13 13:04:42 Created embedding for chunk /Users/home/entr/data/md/aggregate.md 0
2025/02/13 13:04:43 Created embedding for chunk /Users/home/entr/data/md/ci.mdx 0
2025/02/13 13:04:44 Created embedding for chunk /Users/home/entr/data/md/ci.mdx 1
2025/02/13 13:04:45 Created embedding for chunk /Users/home/entr/data/md/ci.mdx 2
2025/02/13 13:04:46 Created embedding for chunk /Users/home/entr/data/md/code-gen.md 0
2025/02/13 13:04:47 Created embedding for chunk /Users/home/entr/data/md/code-gen.md 1
Asking questions
Now that we have loaded the documents and created embeddings for the chunks, we can implement
the AskCmd command to ask questions about the indexed documents. Open the cmd/entrag/rag.go file and add the following code:
// Run is the method called when the "ask" command is executed.
func (cmd *AskCmd) Run(ctx *CLI) error {
client, err := ctx.entClient()
if err != nil {
return fmt.Errorf("failed opening connection to postgres: %w", err)
}
question := cmd.Text
emb := getEmbedding(question)
embVec := pgvector.NewVector(emb)
embs := client.Embedding.
Query().
Order(func(s *sql.Selector) {
s.OrderExpr(sql.ExprP("embedding <-> $1", embVec))
}).
WithChunk().
Limit(5).
AllX(context.Background())
b := strings.Builder{}
for _, e := range embs {
chnk := e.Edges.Chunk
b.WriteString(fmt.Sprintf("From file: %v\n", chnk.Path))
b.WriteString(chnk.Data)
}
query := fmt.Sprintf(`Use the below information from the ent docs to answer the subsequent question.
Information:
%v
Question: %v`, b.String(), question)
oac := openai.NewClient(ctx.OpenAIKey)
resp, err := oac.CreateChatCompletion(
context.Background(),
openai.ChatCompletionRequest{
Model: openai.GPT4o,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
Content: query,
},
},
},
)
if err != nil {
return fmt.Errorf("error creating chat completion: %v", err)
}
choice := resp.Choices[0]
out, err := glamour.Render(choice.Message.Content, "dark")
fmt.Print(out)
return nil
}
This is where all of the parts come together. After preparing our database with the documents and their embeddings, we
can now ask questions about them. Let's break down the AskCmd command:
emb := getEmbedding(question)
embVec := pgvector.NewVector(emb)
embs := client.Embedding.
Query().
Order(func(s *sql.Selector) {
s.OrderExpr(sql.ExprP("embedding <-> $1", embVec))
}).
WithChunk().
Limit(5).
AllX(context.Background())
We begin by transforming the user's question into a vector using the OpenAI API. Using this vector we would like
to find the most similar embeddings in our database. We query the database for the embeddings, order them by similarity
using pgvector's <-> operator, and limit the results to the top 5.
for _, e := range embs {
chnk := e.Edges.Chunk
b.WriteString(fmt.Sprintf("From file: %v\n", chnk.Path))
b.WriteString(chnk.Data)
}
query := fmt.Sprintf(`Use the below information from the ent docs to answer the subsequent question.
Information:
%v
Question: %v`, b.String(), question)
Next, we prepare the information from the top 5 chunks to be used as context for the question. We then format the question and the context into a single string.
oac := openai.NewClient(ctx.OpenAIKey)
resp, err := oac.CreateChatCompletion(
context.Background(),
openai.ChatCompletionRequest{
Model: openai.GPT4o,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
Content: query,
},
},
},
)
if err != nil {
return fmt.Errorf("error creating chat completion: %v", err)
}
choice := resp.Choices[0]
out, err := glamour.Render(choice.Message.Content, "dark")
fmt.Print(out)
Then, we use the OpenAI API to generate a response to the question. We pass the question and context to the API
and receive a response. We then render the response using the glamour package to display it in the terminal.
Before running the ask command, let's install the glamour package:
go get github.com/charmbracelet/glamour
Finally, let's run the ask command to ask a question about the indexed documents:
go run ./cmd/entrag ask "tl;dr What is Ent?"
And our RAG system responds:
Ent is an open-source entity framework (ORM) for the Go programming language. It
allows developers to define data models or graph-structures in Go code. Ent
emphasizes principles such as schema as code, a statically typed and explicit
API generated through codegen, simple queries and graph traversals, statically
typed predicates, and storage agnosticism. It supports various databases,
including MySQL, MariaDB, PostgreSQL, SQLite, and Gremlin-based graph databases,
and aims to enhance productivity in Go development.
Amazing! We have successfully built a RAG system using Ent, Atlas, and pgvector. We can now ask questions about the documents we loaded into the database and receive context-aware responses.
Here are some more Q&As with our nifty RAG system:
go run ./cmd/entrag ask "how to define order field in entgql"
Choose a Comparable Field: Select the field in your schema that you want to be orderable. This could be a text field, a timestamp, an integer, an enum, etc.
Annotate the Field: Use the entgql.OrderField annotation on the chosen field. The order field name should be uppercase and match its corresponding enum value in the GraphQL schema.
Update your Schema: Here’s an example of how to annotate your fields in the ent/schema :
func (Todo) Fields() []ent.Field {
return []ent.Field{
field.Text("text").
NotEmpty().
Annotations(
entgql.OrderField("TEXT"),
),
field.Time("created_at").
Default(time.Now).
Immutable().
Annotations(
entgql.OrderField("CREATED_AT"),
),
field.Enum("status").
NamedValues(
"InProgress", "IN_PROGRESS",
"Completed", "COMPLETED",
).
Default("IN_PROGRESS").
Annotations(
entgql.OrderField("STATUS"),
),
field.Int("priority").
Default(0).
Annotations(
entgql.OrderField("PRIORITY"),
),
}
}Alternatively, Multiple Order Fields: If you want to enable ordering by multiple fields, you can use the entgql.MultiOrder() annotation:
func (Todo) Annotations() []schema.Annotation {
return []schema.Annotation{
entgql.MultiOrder(),
}
}Generate GraphQL Types: Ensure that the GraphQL types match this setup in your GraphQL schema, for example:
enum OrderDirection {
ASC
DESC
}
enum TodoOrderField {
CREATED_AT
PRIORITY
STATUS
TEXT
}
input TodoOrder {
direction: OrderDirection!
field: TodoOrderField
}Add orderBy Argument to Queries: Include the orderBy parameter in your GraphQL queries to allow clients to sort items:
type Query {
todos(
after: Cursor
first: Int
before: Cursor
last: Int
orderBy: TodoOrder
): TodoConnection!
}By following these steps, you ensure that your Ent-based application can support sorting in your GraphQL API based on various fields.
go run ./cmd/entrag ask "what's the difference between privacy rules and interceptors"
- Privacy Rules:
- Purpose: Privacy rules are primarily concerned with enforcing access control policies for data queries and mutations. They determine whether an operation is allowed or denied based on predefined rules.
- Implementation: They are implemented as part of a privacy policy using the ent.Policy interface which includes EvalQuery and EvalMutation methods.
- Operation: Privacy rules evaluate whether specific conditions are met before allowing or denying access to the data. They can return decisions like privacy.Allow , privacy.Deny , or privacy.Skip to control the flow of evaluation.
- Use Case: Ideal for managing access control by ensuring that users can only perform certain operations if they meet the specified criteria.
- Interceptors:
- Purpose: Interceptors act as middleware for Ent queries, allowing modification and customization of query behaviors. They can be used to augment or modify queries during different stages of their lifecycle.
- Implementation: Implemented as interfaces or using the ent.InterceptFunc adapter. They intercept and potentially modify queries by working on the read-path.
- Operation: Interceptors modify or enhance queries, typically without the access control logic inherent in privacy rules. They provide hooks to execute custom logic pre and post query execution.
- Use Case: Suitable for generic transformations or modifications to queries, such as adding default filters, query limitations, or logging operations without focusing on access control.
In summary, while privacy rules focus on access control, interceptors are about managing and modifying the query execution process.
Wrapping up
In this blog post, we explored how to build a RAG system using Ent, Atlas, and pgvector. Special thanks to Eli Bendersky for the informative blog post and for his great Go writing over the years!







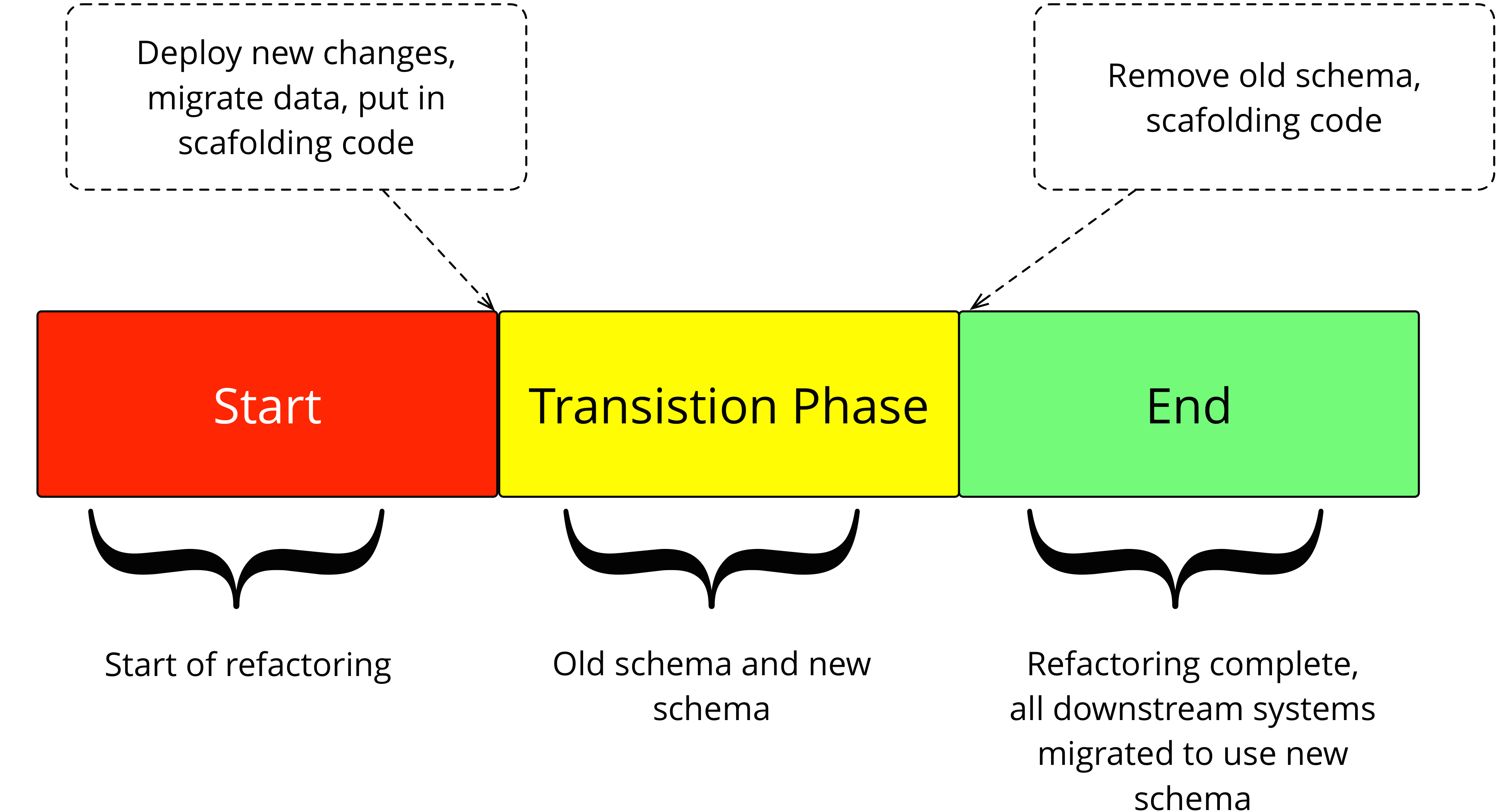 Credit: martinfowler.com
Credit: martinfowler.com 






